Prompts & Agents
How to incorporate prompting into your Python scripts and expand their functionality through agents
Laura Funderburk
PyData Vancouver
Slides: https://tinyurl.com/prompts-and-agents
About me
Developer Advocate @ Ploomber (sharing knowledge about tools to improve the data science workflow)
Previously a data scientist (for-profit, not-for-profit sector)
Deeply curious about generative AI, Large Language Models, with a focus on engineering and automation
I use LLMs, prompting and agents to automate work tasks

Talk at a glance
Part I: Prompting (45 minutes)
- LLMs use cases and tasks
- The Generative AI project lifecycle
- Choosing the right LLM architecture
- Key elements of prompting & prompting techniques
- Prompting private LLMs (OpenAI API):
ChatCompletion - Prompting open source LLMs through HuggingFace
Talk at a glance
Part II: Agents and open source frameworks (15 minutes)
- What are agents
- Introduction to Haystack
- Introduction to LangChain
- Techniques to combine prompting and agents for deployment of applications
- Pros and cons of each
Part I: Prompting
LLMs use cases and tasks
Text summarization
Conversation
Translation
Text generation
Text, token and sentiment classification
Table Q&A and Q&A from unstructured data
Sentence similarity
Masking
LLMs use cases and tasks
Your goal is to understand the business case you are solving - then select the appropriate methods to solve it
$\Rightarrow$ Who will benefit from your product?
$\Rightarrow$ What are business constraints (time, data, resources)?
$\Rightarrow$ What is the end result?
$\Rightarrow$ How will it be served?
The generative AI project lifecycle
Focus of this talk
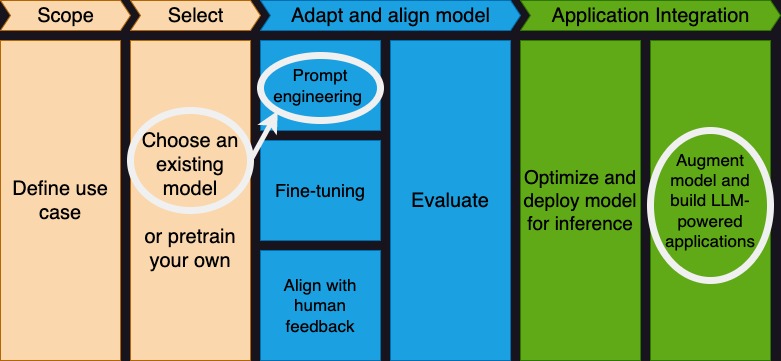
Source: Coursera, Generative AI with LLMs
Choosing the right LLM (architecture)

| Tranformer type | Architecture | Model-like | Focus | Example |
|---|---|---|---|---|
| Auto-regressive | Decoder-only | GPT-like | Generative tasks | Chat bot |
| Auto-encoding | Encoder-only | BERT-like | Understanding of the input | Question-answering |
| Sequence-to-Sequence | Encoder-decoder | BART/T5-like | Generative tasks that require an input | Language translation |
“Attention is all you need” (Vaswani et al. (2017))
Do I need to train a new model to solve my problem?
No. Training an LLM is costly (GPU usage, time, compute, data). This is why sharing LLMs and their fine-tuned components has become highly popular.

You can start with prompting an LLM, then fine-tuning* or using retrieval augmentation if you aren't getting the results you want. You'll need to curate a dataset for this.
*(instruction-tuning or, PEFT + LoRA for example)
Source: https://huggingface.co/tasks
Prompting
Key elements of prompting
Basic

- An LLM to interact with
- Temperature (floating value between 0 and 1)
- Max tokens
- A natural language request
Key elements of prompting
Advanced
- Data (text files, web files)
- A database storage system (vector DB, SQL, PostgreSQL, etc)
- User interfaces
Prompting techniques
Zero-shot inference
One-shot inference
Few-shot inference
Roles (OpenAI API)
Prompting private LLMs (OpenAI API)
We're going to focus on the ChatCompletion end point.
Key elements: OpenAI API Key, model (GPT4, GPT 3.5 Turbo, Text-Davinci), temperature, prompt, max tokens
Prompting techniques: Zero-shot inference
Formula: instruction, no examples.
Suppose we want to translate a natural language question to SQL.
prompt = f"Answer the question {natural_question} \
for table {db_name} \
with schema {schema}"
Prompting techniques: One-shot inference
Formula: instruction, one example.
prompt = f"Answer the question {natural_question} \
for table {db_name} \
with schema {schema}\
Question: How many records are there?\
Answer: SELECT COUNT(*) FROM bank"
Prompting techniques: Few-shot inference
Formula: instruction, more than one example.
prompt= f"Answer the question {natural_question} \
for table {db_name} \
with schema {schema}\
Question: How many records are there?\
Answer: SELECT COUNT(*) FROM bank\
Question: Find all employees that are unemployed\
Answer: SELECT * FROM bank WHERE job = 'unemployed'"
Roles in prompting the ChatCompletion endpoint (OpenAI API and AWS Sagemaker models)
The 'role' can take one of three values: system, user or the assistant
The content contains the text of the message from the role.
system role: You can use a system level instruction to guide your model's behavior throughout the conversation.
You are a helpful ... with knowledge about ...user role: What are typical requests that someone in that role would receive?
Answer the question ... assistant role: This role represents the language model, such as ChatGPT, which generates responses based on the provided user messages.
Business problem: translate natural language questions into SQL
We can solve this problem with prompting and the ChatCompletion endpoint on the OpenAI API.
Approach: build a Prompter class and add each prompting technique as a method, then evaluate results
Approach: initialize a Prompter class
import openai
class Prompter:
def __init__(self, api_key, gpt_model, temperature=0.2):
if not api_key:
raise Exception("Please provide the OpenAI API key")
self.api_key = api_key
self.gpt_model = gpt_model
self.temperature = temperature
Approach: add a chat completion method to call a GPT-like model (OpenAI API)

Approach: add a method with a single-shot prompt and the assistant role

Approach: add a method with a system and user roles

Evaluate results
Let's suppose I have a DuckDB in-memory instance with a table called bank that looks as follows.
%sqlcmd explore --table bank
Evaluate results
Let's take the different prompting techniques for a ride.
We will ask the OpenAI API GPT-3.5-turbo model to translate a natural language question into SQL.
pm = Prompter(open_ai_key, "gpt-3.5-turbo")
Zero-shot results.
pm.natural_language_zero_shot("bank",
column_names,
"How many unique jobs are there?")
'To determine the number of unique jobs in the table "bank", we need to look at the distinct values in the "job" column.'
pm.natural_language_zero_shot("bank",
column_names,
"What is the total balance for \
employees by education?")
'I\'m sorry, but I cannot provide the answer to that question as it requires access to specific data from the "bank" table.'
Few-shot results.
pm.natural_language_few_shot("bank",
column_names,
"How many unique jobs are there?")
'Question: How many unique jobs are there?\nAnswer: SELECT COUNT(DISTINCT job) FROM bank'
pm.natural_language_few_shot("bank",
column_names,
"What is the total balance for \
employees by education?")
'Answer: The total balance for employees by education can be found by grouping the data by education and summing the balance column. The query would be:\n\nSELECT education, SUM(balance) AS total_balance\nFROM bank\nGROUP BY education;'
Roles-based results.
pm.natural_language_with_roles("bank",
column_names,
"How many unique jobs are there?")
'SELECT COUNT(DISTINCT job) FROM bank'
pm.natural_language_with_roles("bank",
column_names,
"What is the total balance for\
employees by education?")
'SELECT education, SUM(balance) AS total_balance FROM bank GROUP BY education'
%%sql
SELECT education, SUM(balance) AS total_balance
FROM bank GROUP BY education;
| education | total_balance |
|---|---|
| primary | 957027 |
| secondary | 2759854 |
| tertiary | 2396822 |
| unknown | 318133 |
Prompting open source LLMs through HuggingFace
You need to ensure you install the right modules via pip along with any modules specified in the model card of the LLM (transformers).
The reality of prompting open source models

The reality of prompting open source models
- HuggingFace hosted models resemble GitHub repos (but not in a good way).
- You will need to feel comfortable using the
transformers,PyTorchandTensorFlowlibraries. - You will need a bit more than just comfort with the transformer architectures.
- Dependency hell.
- Prompting results vary across different models.
- Model documentation ranges from non-existent to highly technical (research papers).
- Higher likelihood that you'll need to find the base model and fine-tune with your data for better results.
Prompting a T5-like model to translate NL to SQL
We will explore the functionality of fine-tuned T5 model via the id
mrm8488/t5-base-finetuned-wikiSQL
Remember that T5-like models are of type encoder-decoder and good at translating between languages.
This model was fine-tuned on the wiki-SQL dataset.
Note that this model was not instruction-tuned

def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text],
return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
max_new_tokens=200)
return tokenizer.decode(output[0])
# Translate
natural_question = "How many entries are there?"
db_name = "banks"
schema = column_names
prompt = f"{natural_question} \
for table {db_name} \
with schema {schema}"
get_sql(prompt)
"<pad> SELECT COUNT Table FROM table WHERE Schema = ['age', 'job','marital', 'education', 'default', 'balance', 'housing', 'loan', 'contact', 'day','month', 'duration', 'campaign', 'pdays', 'previous', 'poutcome', 'y</s>"
How to guide your choices
- Remember your use case, the business constraints and who will use your application
- Remember the three base models and their keywords
- Choose instruction-tuned foundation models as a starting point for fine-tuning or retrieval augmentation.
| Tranformer type | Architecture | Model-like | Focus | Example |
|---|---|---|---|---|
| Auto-regressive | Decoder-only | GPT-like | Generative tasks | Chat bot |
| Auto-encoding | Encoder-only | BERT-like | Understanding of the input | Question-answering |
| Sequence-to-Sequence | Encoder-decoder | BART/T5-like | Generative tasks that require an input | Language translation |
Part II: Agents and open source frameworks
We will now turn our attention to two open-source frameworks you can use to augment the functionality of prompting through agents: LangChain and Haystack.
The frameworks introduced here can both be installed via pip and imported as modules into your Python script.
What are agents
The role of an agent is to empower LLMs to decide which actions to take, thereby granting them a certain degree of autonomy. In simple terms, agents are a fusion of LLM chains (which are sequences of LLMs) and tools.
Introducing LangChain
LangChain is a framework for developing applications powered by language models. It enables applications that are:
Data-aware: connect a language model to other sources of data
Agentic: allow a language model to interact with its environment
How does LangChain approach Agents?
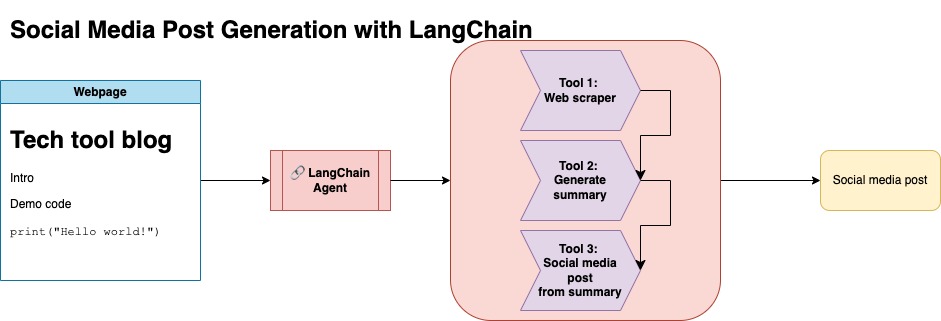
With LangChain we think in terms of components and off-the-shelf chains.
How to incorporate it into your scripts
You can build your custom functions in Python and use their @tool decorator.
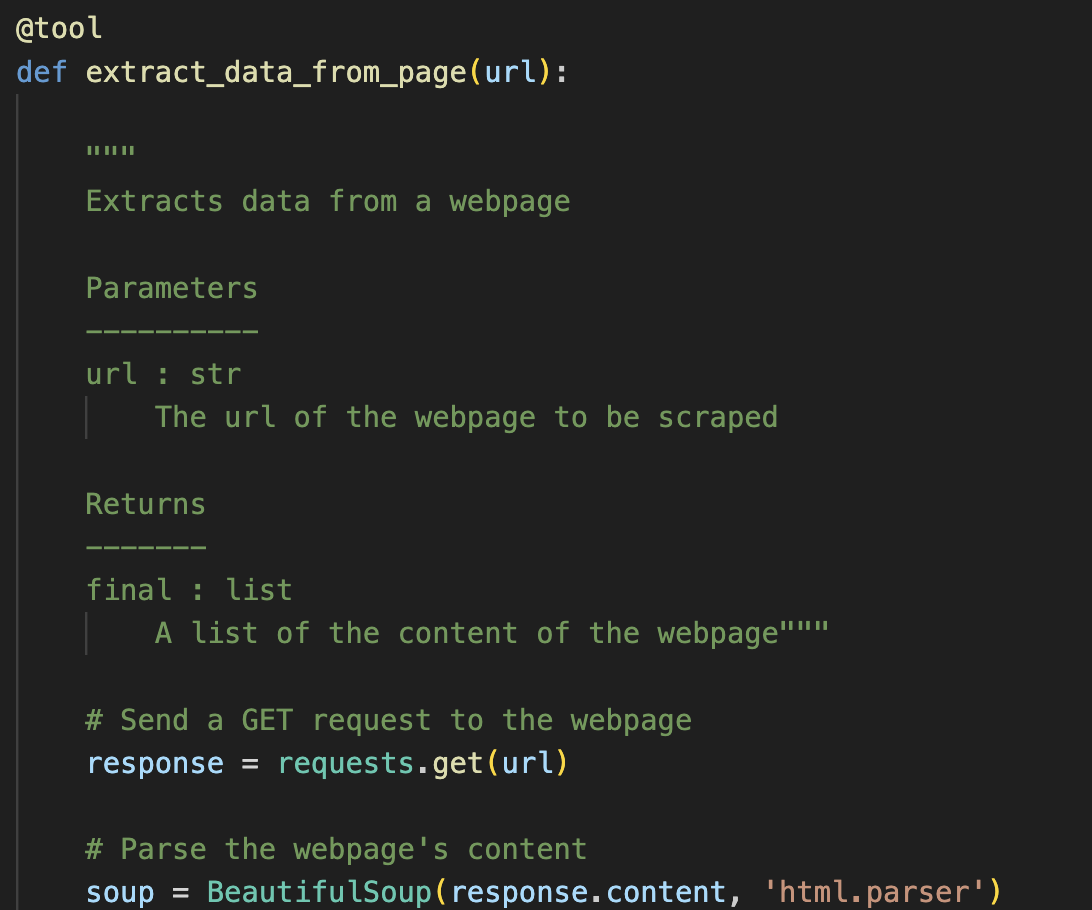 |
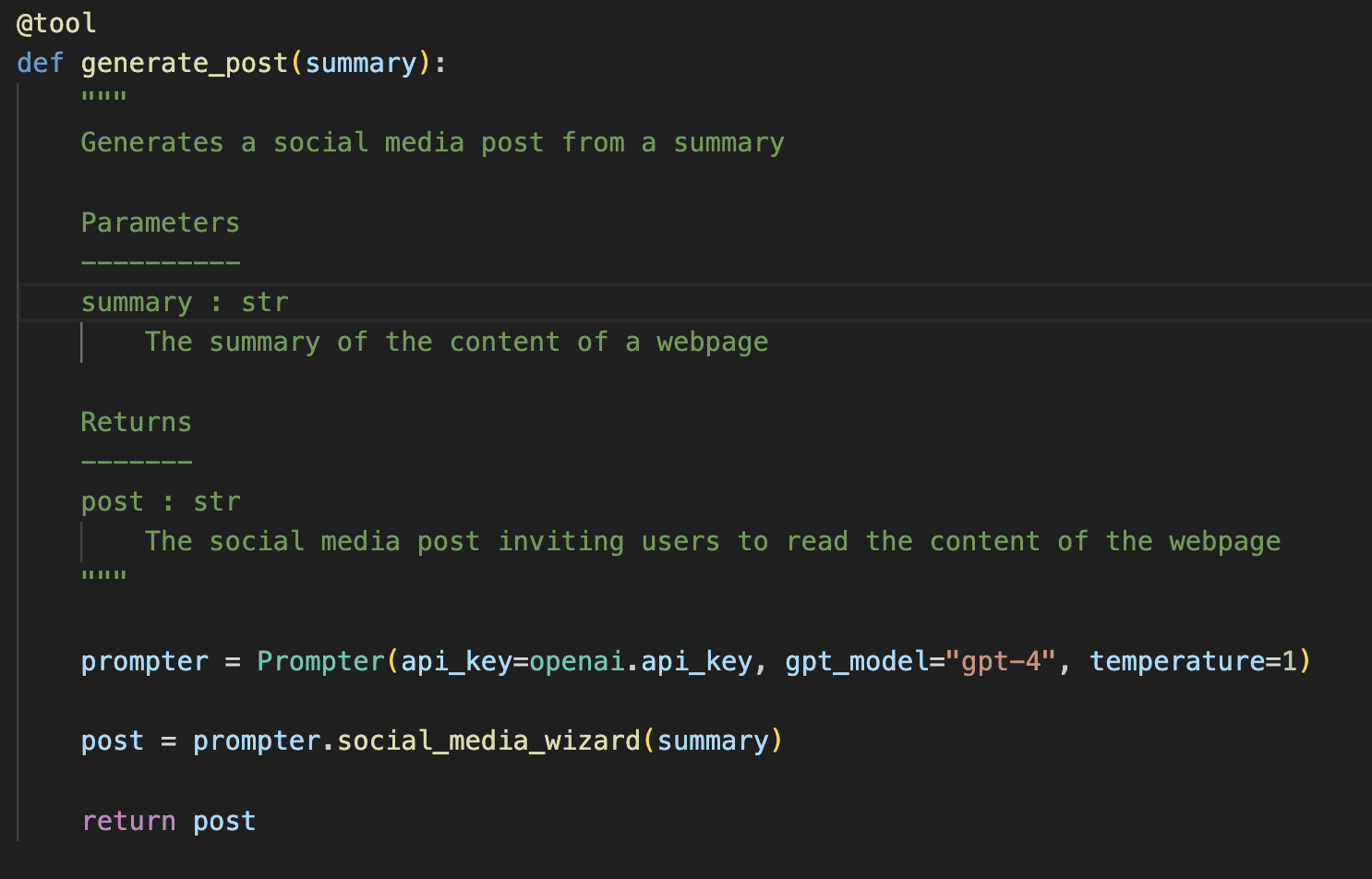 |
How to incorporate it into your scripts
Then after initializing LangChain along with the GPT model you want, you can then ask it to perform tasks with natural language commands.
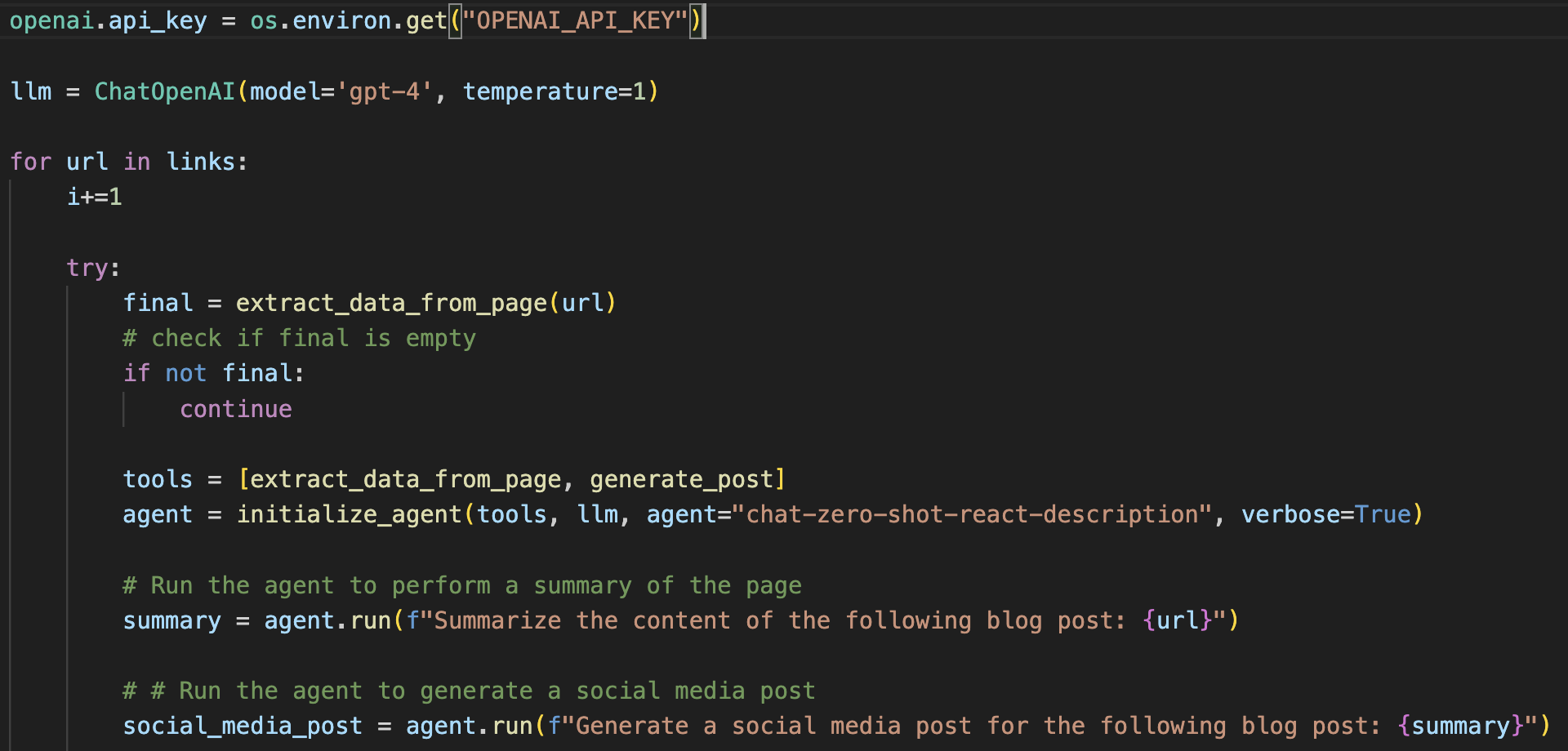
LangChain Pros & Cons
Pros
- May be helpful as a way to get started with prompting the OpenAI API
- Maps easily to OpenAI API chat completion end point
- Enabled embeddings workflow (vector DB)
Cons
- Hype
- Security concerns
- Evaluation of results
- Currently not production friendly
- In early stages
- Increases cost of OpenAI API usage (hidden prompting)
Introducing Haystack

Haystack is an open-source framework for building search systems that work intelligently over large document collections.
Deepset is an open source startup that empowers developers to build flexible and semantic search systems to query all types of data using the Haystack framework.
Functionality:
- Call open source models, hosted models (Azure, AWS) as well as private ones (OpenAI API)
- Build production-ready NLP pipelines with their custom-built tools
- Machinery for unstructured data processing (text)
- Leverage their prompt templates (prompt-hub)
- Incorporate Agents
- Compatibility with Vector and classic DB.
- Deploy via REST API
How does Haystack approach Agents?
Nodes: each Node achieves one thing
Pipelines: this is the standard Haystack structure that can connect to your data and perform on it NLP tasks that you define.
Document stores: designed to make document retrieval and processing easier, can be connected to nodes via pipelines.
Tools: you can think of a Tool as an expert, that is able to do something really well.
Agent: a component that is powered by an LLM, such as GPT-3. It can use tools and decide on the next best course of action so as to get to the result of a query.
Creating a custom node to perform SQL queries in Jupyter
We are going to use JupySQL to perform the quries.
JupySQL was developed on top of iPython-SQL and its purpose is to connect to DBs of various flavours and execute queries within Jupyter notebooks with the magics %sql and %%sql.
Let's define JupySQLQuery as a node. We can do this by creating is as a subclass of the haystack.nodes.base.BaseComponent class in Haystack.
Initialize JupySQL - this is a tool that can execute queries from Jupyter via the %sql and %%sql magics.
from haystack.nodes.base import BaseComponent
class JupySQLQuery(BaseComponent):
outgoing_edges = 1
def __init__(self):
%reload_ext sql
%sql duckdb:///bank.duck.db
Add a method to execute one query via the %sql magic.
from haystack.nodes.base import BaseComponent
class JupySQLQuery(BaseComponent):
...
def run(self, query: str):
result = %sql {{query}}
output = {
"results": f"{result}",
"query": query,
}
return output
Add a method to execute a list of queries via the %sql magic.
from haystack.nodes.base import BaseComponent
class JupySQLQuery(BaseComponent):
...
def run_batch(self, queries: list):
results = []
for query in queries:
result = %sql {query}
output = {
"results": f"{result}",
"query": query,
}
results.append(output)
return results
from haystack.agents import Tool
from haystack.nodes import PromptNode
from jupysqlagent import sql_agent_prompt
from haystack.agents import Agent, Tool
# Initialize node
jupy_sql_query = JupySQLQuery()
# Define a tool with our new node
jupy_sql_query_tool = Tool(name="JupySQL_Query",
pipeline_or_node=jupy_sql_query,
description="""This tool is useful for \
consuming SQL queries \
and responds with the \
result""")
# Get the API key
openai_api_key = os.environ.get("openai-key")
chosen_model = "gpt-4"
# Define a prompt node that uses the GPT-4 model
prompt_node = PromptNode(model_name_or_path=chosen_model,
api_key=openai_api_key,
stop_words=["Observation:"],
max_length=1000)
# Define the agent
agent = Agent(prompt_node=prompt_node,
prompt_template=sql_agent_prompt)
agent.add_tool(jupy_sql_query_tool)
result = agent.run("How many records are there")
Agent custom-at-query-time started with {'query': 'How many records are there', 'params': None}
count the total number of records in the table 'bank'. I can do this directly via an SQL query.
Tool: JupySQL_Query
Tool Input: "select count(*) from bank"
Observation: +--------------+ | count_star() | +--------------+ | 4521 | +--------------+ Thought: The query returned the total number of records in the 'bank' table. Final Answer: There are 4521 records in the table.
result = agent.run("How many unique levels of education are there")
Agent custom-at-query-time started with {'query': 'How many unique levels of education are there', 'params': None}
identify the unique values in the 'education' column of the 'bank' table. I will use the DISTINCT keyword in SQL to do this.
Tool: JupySQL_Query
Tool Input: "select distinct education from bank"
Observation: +-----------+ | education | +-----------+ | primary | | secondary | | tertiary | | unknown | +-----------+ Thought: There are four unique levels of education from the bank table. Final Answer: There are four unique levels of education: primary, secondary, tertiary, and unknown.
Haystack Pros & Cons
Pros
- Established framework with a focus on production-ready NLP applications
- Constantly adapting to new changes and building on top of their framework
- Deployment-friendly (REST API)
- Offers solutions for your custom documents and access to a variety of database flavours
- Offers prompt templates
Cons
- Steeper learning curve (requires comfort with more structure and OOP)
- Limitations on the types of files it can handle (PDF and markdown currently not supported)
- Narrower focus when it comes to the types of agents it supports (although you can create custom agents, through custom nodes)
Final thoughts
- Prompt-engineering starts with a well defined project and a clear choice of transformer architecture
- Prompting is usually the first step when using an LLM
- Prompting via the OpenAI API provides a quick solution to prototype, but has limitations when it comes to private data/documents
- Prompting open source LLMs requires understanding of transformer architecture and openness to fine-tune
- We explored two open source frameworks that allow you to augment the funcionality of LLMs via agents
- LangChain approaches agents through components and chains
- Haystack approaches agents in terms of expanding the funcionality of prompt nodes, pipelines and a document store.
Connect with me!
Slides: https://tinyurl.com/prompts-and-agents